11 Reproducible Analyses
11.1 Why start with reproducible analysis workflows?
Although ZOO/ECOL-5500 focuses on quantitative analysis and modeling, those tools are only as reliable as the infrastructure that supports them. Establishing a clear, reproducible workflow creates a solid foundation that can scale appropriately as new data arrive –whether that means new sensor downloads, ongoing field observations, or ever-expanding datasets– without requiring you to constantly restructure, reinvent, or debug your analysis.
This chapter provides the broad conceptual map for the rest of Part I. Subsequent chapters focus on individual components of this workflow.
11.2 Analytical Workflow
A statistical philosophy only works if it is supported by a deliberate, reproducible analytical workflow. This workflow description is doing a lot of work, so let us be very clear about the meaning.
Analytical workflow: The data and computational infrastructure that translates raw observations into scientifically defensible results and inferences.
A workflow include everything about how datasets are stored, cleaned, explored, modeled, and reported. Importantly, it also includes how decisions are documented and how analyses can be reproduced by someone else (including your future, more frenetic self).
Designing a good analytical workflow is hardly a casual endeavor. In fact, it should be a target of formal and toughtful analysis itself, answering questions like:
- Is your workflow efficient in terms of your valuable time?
- Is your workflow efficient in terms of your computational infrastucture and abilities?
- Is your workflow clear, or does it create confusion and induce mission/scope creep?
- Does your workflow allow you to stop and restart without losing your place?
A good workflow constrains your behavior in productive ways. It limits wandering, enforces transparency, and makes progress visible. That is, there is no single correct workflow. As Rudyard Kipling wrote (In the Neolithic Age):
Here’s my wisdom for your use, as I learned it when the moose And the reindeer roamed where Paris roars to-night: “There are nine and sixty ways of constructing tribal lays, And—every—single—one—of—them—is—right!
There are many ways of constructing something useful and meaningful, and every single one of them can be right. What matters is that your workflow is intentional, scientifically defensible, and aligned with your scientific goals. So, I encourage you to start formalizing a philosophical workflow that reduces bias, controls scope, and supports efficient thinking. Then stick to it until you learn something better. That moment will come, and when it does, simply update your philosophy through slow iteration rather than abandoning it.
11.3 What is a reproducible analytical workflow?
A common misconception—especially early in graduate training—is that reproducibility means sharing files and code on GitHub, Dryad, or similar repositories. Those components are necessary, but they is not sufficient.
A reproducible analytical workflow is a structured system that explicitly and completely describes how scientific results are generated. Such a workflow:
- starts with observations of the world, not the computer
- treats measurement as a translation (or signal-transduction) process
- clearly and explicitly documents where data come from
- separates data, metadata, processing, and inference
- records inputs → transformations → outputs at each step (this is key!)
- makes explicit where assumptions or biases are introduced
- allows another person (or you, six months later) to reconstruct the results
Together, these features ensure that analyses can be understood, repeated, extended, and scaled as new data arrive.
11.4 The reproducible analytical workflow as a causal system
The reproducible analytical workflow can be understood as a causal system in which each step produces downstream consequences: measurement choices shape the raw data, data processing constrains what can be modeled, and modeling assumptions determine what can be inferred. Thinking causally about the workflow makes it clear that results do not simply “come from the data,” but from a chain of decisions that can be traced, tested, and reproduced. Generally, this pipeline looks like this:
World → Data → Models → Inference → Interpretation
More explicitly, as seen in the diagram at right, we have the following general steps:
- World / phenomena: Processes exist whether or not we observe them (or like them!)
- Measurement & observation: Instruments and observers translate phenomena into recorded values.
- Raw data + metadata: Raw data must have metadata as context.
- Processing & derivation: Filtering, organizing, feature extraction, etc.
- Models & inference rules: Assumptions can be documented and coded explicitly.
- Interpretation: Human judgment (which is usually not reproducible, unless codified).
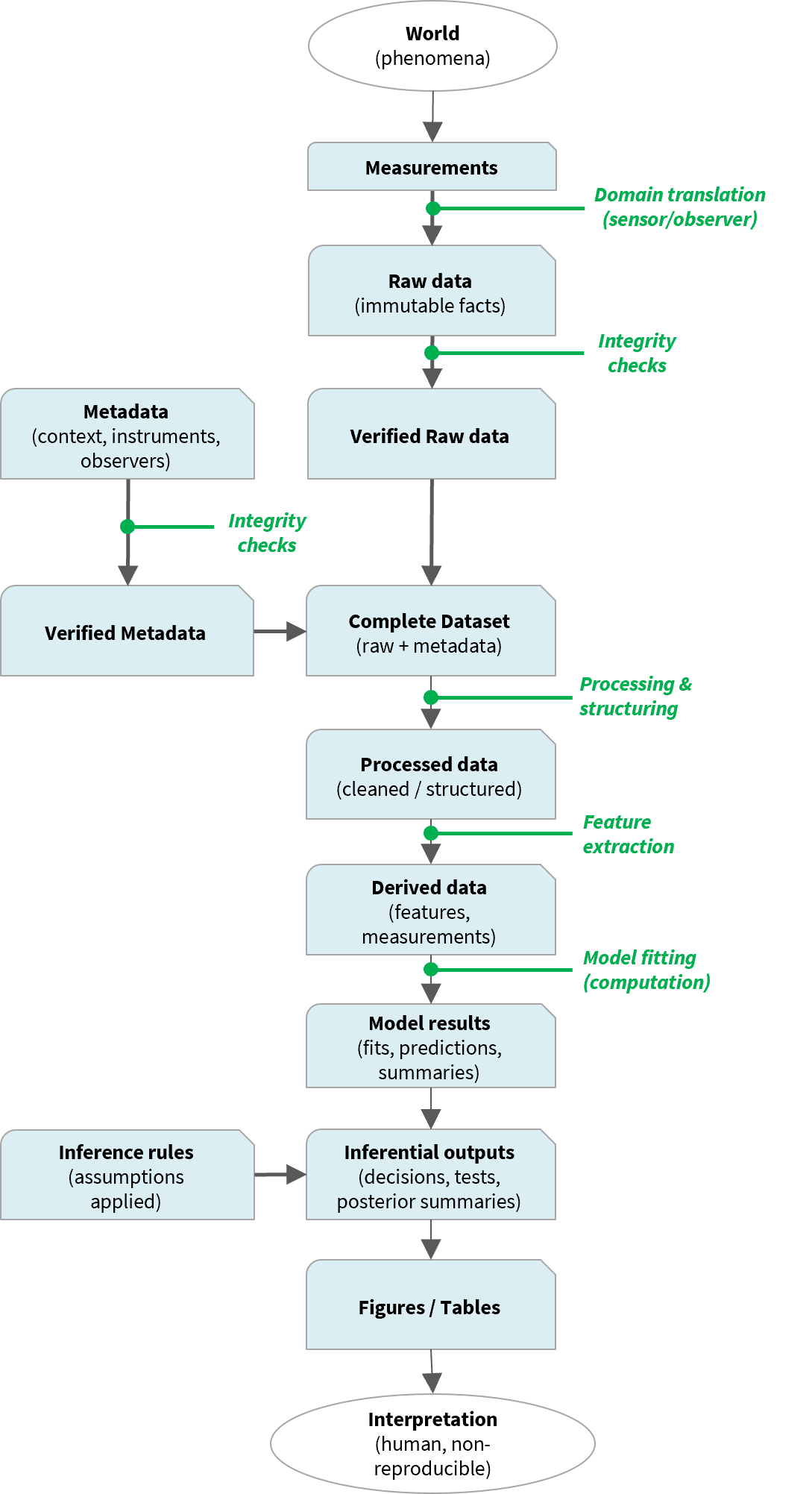
Everything up to (and including) production of figures and tables can and should be reproducible. That is, (1) you should be able to rerun an entire analysis and produce tables and figures (and fill in values in a Results section) with a simple click of a button, and (2) another user should be able to reproduce all steps in your analysis pipeline, even with minimal code. Framing the workflow as a casual path makes obvious how each result is causally linked to specific inputs, transformations, and assumptions.
11.5 Why workflows matter scientifically
Reproducibility in a scientific workflow is not primarily about convenience, though it often becomes convenient over time. A convenient –but non-reproducible– workflow focuses on rerunning an analysis quickly, often relying on memory, manual steps, and undocumented choices. That approach may work in the short term, but it does not scale and rarely holds up weeks, months, or years later. A reproducible workflow, by contrast, is designed so that every result can be traced back to its origins, including the data, code, assumptions, and decisions that produced it.
At a broader scale, reproducible workflows allow us to:
- diagnose errors
- understand sensitivity to assumptions
- reuse data responsibly
- build on previous work without re-guessing decisions
- reduce long-term computational and cognitive overhead
In short:
- Convenience: “Can I run this analysis again?”
- Reproducibility: “Can I clearly show how these results were produced?”
11.6 How Part I: Reproducible Analyses is organized
This Part follows the workflow in stages:
- Nature of data: What data are, how measurement works, and what raw data means.
- Metadata (low friction): How to document context without drowning in formatting standards.
- Reproducible workflows: Why multiple step-by-step scripts are not enough; the need for explicit input–output mapping.
- Inference and interpretation: Where assumptions enter and where reproducibility ends.
Each chapter is responsible for a specific region of the workflow.
11.7 A guiding principle
If you cannot say what a result depends on, it is not reproducible.
Keep this sentence in mind as you move forward. The next chapter starts where all workflows begin: with the nature of data themselves.
11.8 A parting note
In the next section, I take a step back and offer a set of statistical aphorisms that can help us remain vigilane about workflow weaknesses, leaky assumptions, incorrect modeling approach, or cryptic biases.